


As the old song goes: “How do you solve a problem like managing hundreds of thousands of user-generated files in a way that provides quick access, organizability and searchability, while also keeping a low barrier to entry and minimising resource usage?”. Ok, that might not be exactly how it went, but it’s what we’re covering in today’s Arkenforge Devlog – Content Management

It took quite a few iterations to reach the point we’re at, and there will probably be more in the future. Each step has solved new sets of problems that have arisen as the Toolkit has grown and developed over the years, and as our community has become more and more ambitious with their content usage. For anyone else building a VTT, or really any platform that required file management on a large scale, this article is for you! If you aren’t a developer, have a read anyway 🙂
This follows on from our previous article on the subject from 2020. We’ll summarise it below in the ‘early years’ section, but you can read the full article here: https://arkenforge.com/content-management-and-arkenforge-a-history/

The early years: 2017 – 2020
Did we know what we were doing? It’s a strong maybe.
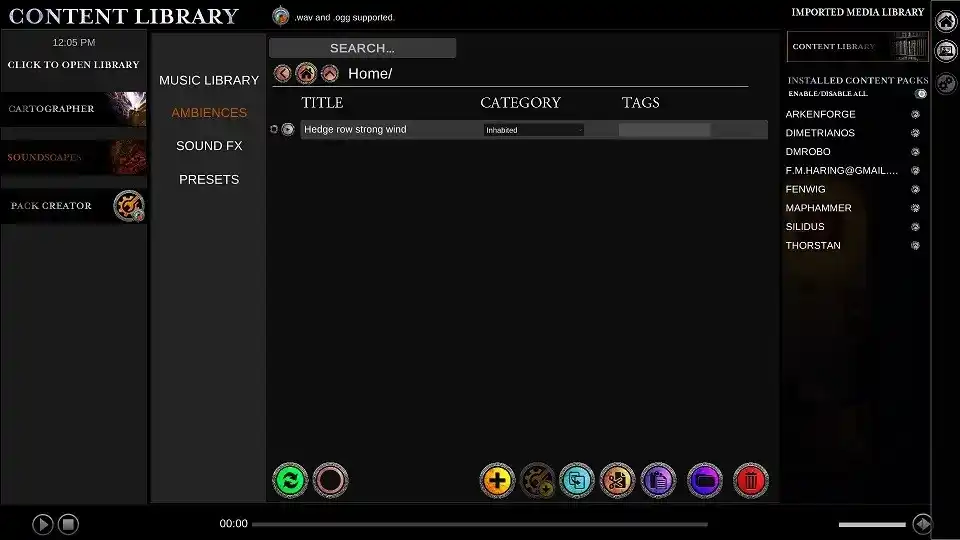
The Arkenforge Toolkit is locally installed software. That gives us challenges that many online platforms don’t have to deal with. Mainly – that the only limit to your content library is your hard drive space.
We went through a lot of iterations, from a 5gb file that was loaded directly into RAM, to a map asset management system that was easy to use, but incredibly convoluted to configure. Eventually we landed on a system that allowed users to easily see their imported content, but made it difficult to actually use that content in many cases.
At the start of 2020, COVID appeared on the global stage. Throughout most of 2020 and a good portion of 2021, we were locked down in Melbourne. As we couldn’t go to conventions, or really leave the house much at all at times, we decided that we’d go through and fully redesign the Toolkit. When it came to the content system, the version at the time had its flaws. There were issues with content management and usability of imported assets. Primarily, users with lots of content could take 15 – 20 minutes to load the Arkenforge Toolkit software. This had to change.

The Problems
We identified two core problems with our current content management system. Two problems doesn’t sound like a lot, but they were large problems. Problems that went to the very core of how the Arkenforge Toolkit software operated.
1. The content loading problem
You see, meta files were an incredibly useful tool. But, while we lazy-loaded the main content, all meta files were loaded into the Toolkit in RAM. This essentially brought us back to the .rwpack days of old, but with significantly smaller file sizes. The main issue here was our power users that had imported huge quantities of map assets. When the Toolkit was launched, it would go through every folder in the ArkenforgeData folder to find the meta files it would load into the Toolkit. When you’re dealing with tens, if not hundreds of thousands of files, this takes quite a long time. Effectively, we were punishing users for using more of the Toolkit.
Not a great thing to do.
2. The content organisation problem
We were also still using the Palette Tool. It was an excellent function back in the early days of the Toolkit, but like much of the UI, it was quickly becoming unfit for purpose. Not only did it limit things to category/subcategory, leading to large amounts of content in each subcategory, but when users were importing content they would have to create their own categories to move their content to. With the benefit of hindsight, this was a terrible idea. However, progress occurs incrementally, and this was needed to increment upon.
So, we needed to find a way to stop all of these files loading in at runtime, but still be able to access them when needed. We also had to give users a way to easily manage their imported content, without having to spend hours creating categories to assign that content to. There was a clear solution.
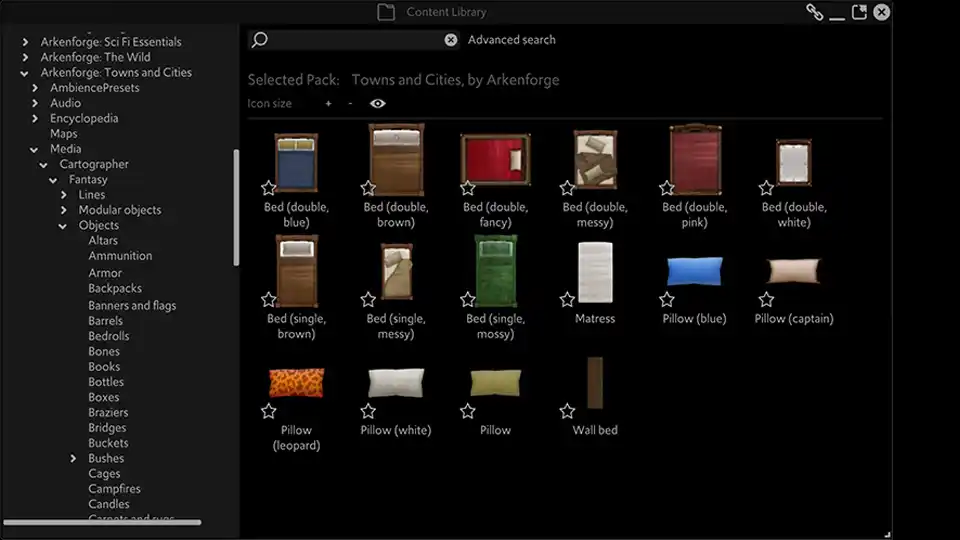
2021: The new file system
There’s already something out there that provides a clear way to organise files. One that requires minimal effort on part of the user and allows new files to be added and accessed immediately. One that you’re using right now to read this article.
An operating system.
It was a bafflingly simply solution. Mimic the operating system’s folder structure, and show content as it’s physically organised on the computer. How hadn’t we thought of it earlier? Well, honestly we hadn’t needed to.
So, we updated the Content Library once more. We put in fixed folders that each content type would be placed in. Users could create their own custom folders within them. This kept content where it should be, and it let users easily organise their imported content. We could also use this system with our content packs. It allowed us to split content into a greater number of categories, and eventually genres, keeping the number of assets per folder relatively low.
As we were swapping to a folder-based system, we no longer needed to know every file in the Toolkit. The operating system was handling that for us. This meant that we could now lazy load our meta files as well! Meta files were only loaded when the relevant folder was opened. Some types of files, namely playlists, ambience presets, and SFX triggers, would be loaded in the background when the Toolkit started. This was because audio content could be assigned to them through a right click menu, and if the content wasn’t loaded, it couldn’t appear as an option in those menus. This loading was done in a separate thread after the Toolkit was launched.
Boy, it was nice to have finally solved the problem once and for all! Well, for about two years…
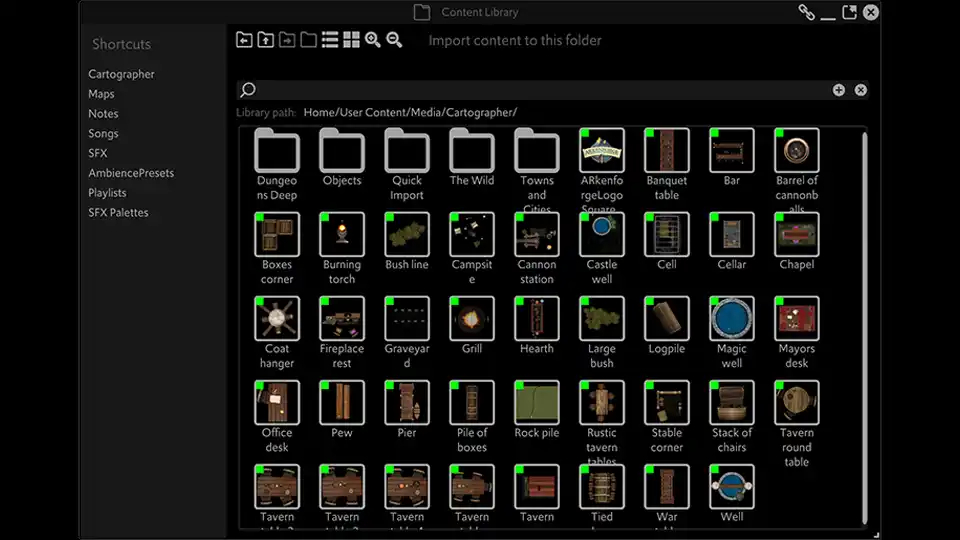
2023: Identifying new problems
With the new changes, the load time for the Toolkit was now effectively zero. All content could now be managed easily through the file browser, so our organisation problem was sorted. All were rejoicing!
But there were small, pesky problems that kept coming up. Our notes system updates meant that people were using them more. That meant lots of data added, and naturally the desire to link all that content together. We’d also optimised our mapping quite heavily, so people could now add more and more assets to their maps. With our new content packs, there were tens of thousands of new assets available to build with.
You can see the singular big problem that this is all leading to.
Searching
How do you search through hundreds of thousands of assets without slowing down, or even in some cases, freezing your software?
Our existing method wasn’t great. Since we were relying on the folder system to show content, we were also relying on it to search content. Do you know how long it takes to search hundreds of thousands of files to find all the trees? Too long. Especially when that process involves opening every meta file in every folder to read the contents. If you could just search by name, the problem wouldn’t be quite as bad. At least then you’d be able to just read the file names without needing to open them. Still a long process, but nowhere near as long as opening the meta files. But no, we gave people filters. Content type, content pack, creator, artist, etc. All data that you can’t easily keep in a file name.
Suffice to say, when you’re dealing with as much content as many of our users, that search began to take a while to return its results. Fortunately there’s a relatively simple solution for this one.

Indexing
An index is essentially a phone directory for your content. When building our index, we essentially pull all of the information out of our meta files and put them into a very long list.
A list of text is significantly faster for a computer to parse than opening and parsing multiple files. It’s even faster when the full list is in RAM. By running our search system off the index rather than the file system, it can find content near instantly. The primary issue at this point is keeping the index properly updated.
Importing and deleting content from the Toolkit updates the index accordingly. For any content not indexed, such as users who copy files into the Toolkit through the OS file browser, individual folders can be reindexed, as can any given content pack, or the entire Toolkit if a user so wishes. We keep the content library using the folder system for this reason. If a user has unindexed content, it can lead to confusion if it doesn’t appear in the content library. When viewed in the content library, all content has a UI element to show its indexed state.
A hidden weakness
The index update also revealed a small weakness of the old system. Some content types didn’t have meta files attached. As these files were rather small, we would just load them directly. In order to index them effectively, we had to create meta files for these types of content. This also meant updating the existing Toolkit systems to base decisions on these meta files, rather than on the content files directly. Something seemingly simple such as dragging and dropping content relies on knowing what type of content is being dragged and dropped. If the content type changes from a Playlist to a Playlist Meta, the logic breaks, because everything was built to handle Playlists.
This change also allowed us to streamline quite a lot of the file management and display code in the Toolkit. When every shown file is a meta file, then we don’t need different classes for the meta-less content types. We removed a lot of conditional logic, which provided a small boost to performance when loading files.
Other benefits
The new Content Library system we’ve built has a few extra features that aid with usability.
Firstly, folders are now treated as a content type. This means that users can drag and drop them onto the Arkenbar, onto the map, or into notes.
We also include folders into the index file. This increases search functionality, as users can add part or all of a folder path as a search filter. This helps when users have multiple instances of content with the same or similar names.
Finally, by unifying our file viewing code to only look at meta files, it allows opportunities in the future for custom folders with mixed media. This would allow audio, images, video, and the various collection-based content types to co-exist in the same folder.
All of these new systems work together to allow our users to find and access their content faster than ever before.
Conclusion
That’s where we with content management are as of the Q2 2024 Arkenforge Toolkit Beta Version. A mixture of native OS folder structures and content indexing that provides management of hundreds of thousands of files while allowing full searchability in under second.
There are some updates that we could make in future, mostly around removing the requirement of every content type needing its own fixed folder structure. This would give users more freedom in managing their content, as well as removing a level of confusion that can arise from where certain types of content are stored. That’ll be quite a large and painful update though, so it likely won’t be happening any time soon.
Thanks for reading, and we’ll see you in the next one!
